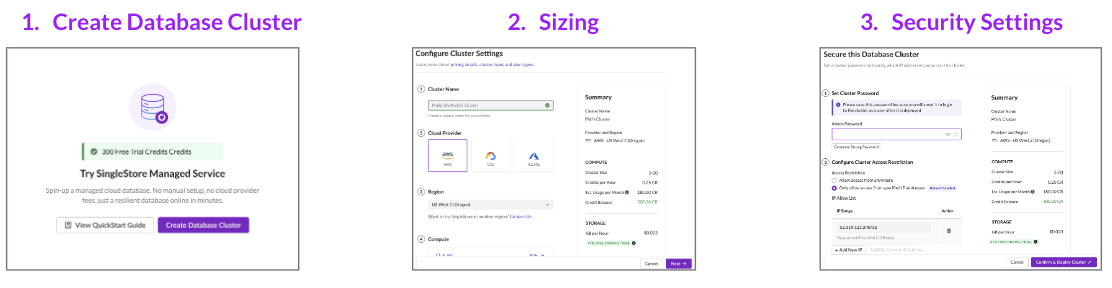
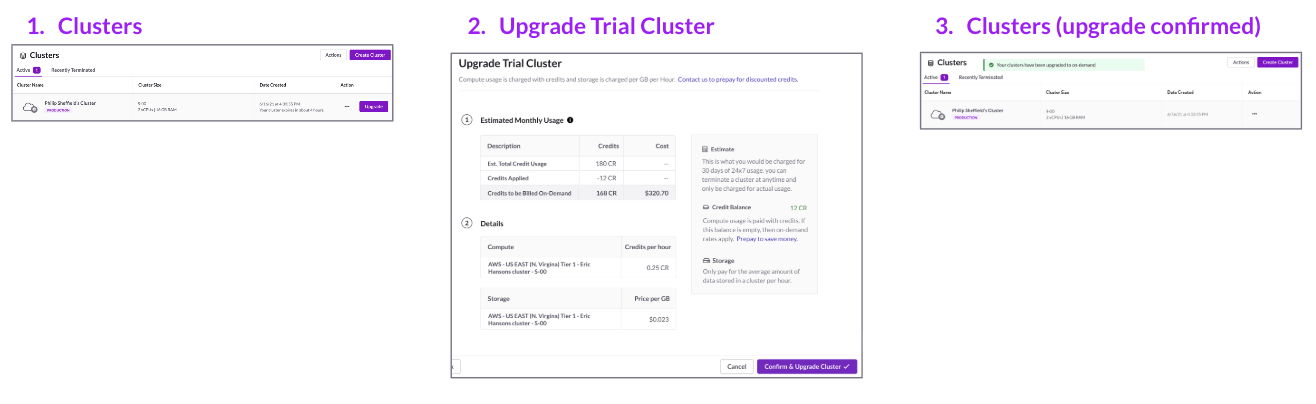
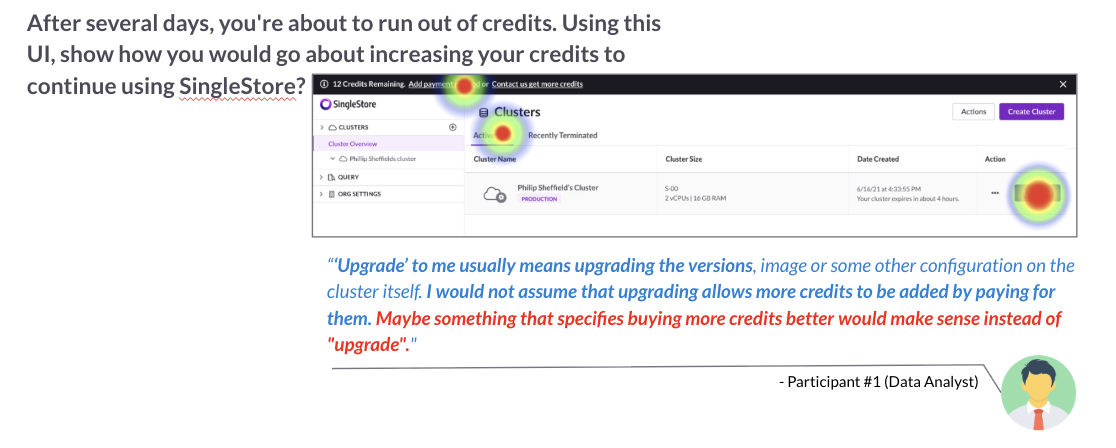
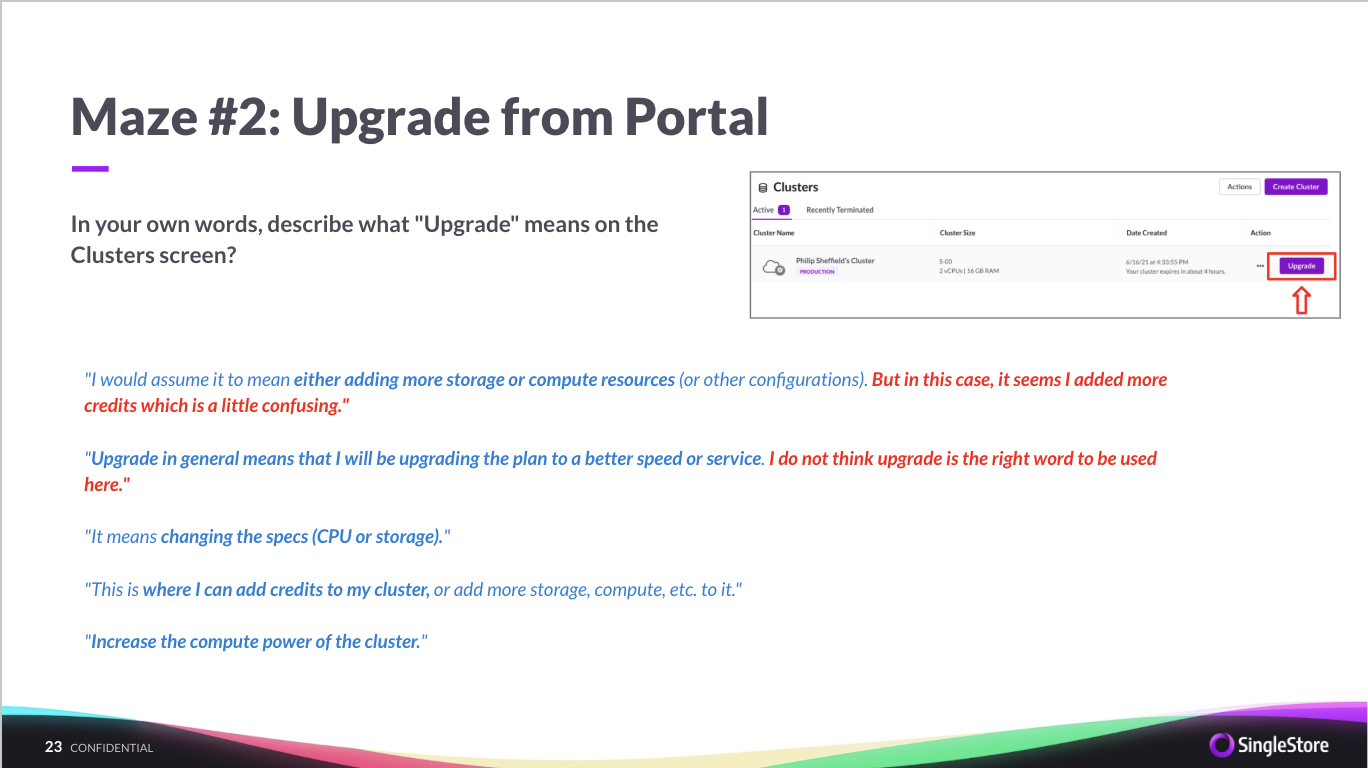
SingleStore's new credit-based pricing model was launching to simplify cluster creation for trial users. However, early beta feedback suggested confusion around how credits were applied, what "upgrade" meant, and how to estimate monthly costs.
This research aimed to identify usability friction in the credit purchase and cluster creation flow before launch, enabling the team to refine terminology and UI clarity to reduce support burden and improve conversion.